스크래피 스파이더가 빈파일을 출력하는 이유를 모르겠어요!
- 1
-
0
책('파이썬을 이용한 웹크롤링과 스크레이핑' )에 첨부된 ch6-1의 myspider.py 입니다.
- import scrapy class BlogSpider(scrapy.Spider): # spider의 이름 name = 'blogspider' # 크롤링을 시작할 URL 리스트 start_urls = ['https://blog.scrapinghub.com'] def parse(self, response): for url in response.css('ul li a::attr("href")').re('.*/category/.*'): yield scrapy.Request(response.urljoin(url), self.parse_titles) def parse_titles(self, response): for post_title in response.css('div.entries > ul > li a::text').extract(): yield {'title': post_title}
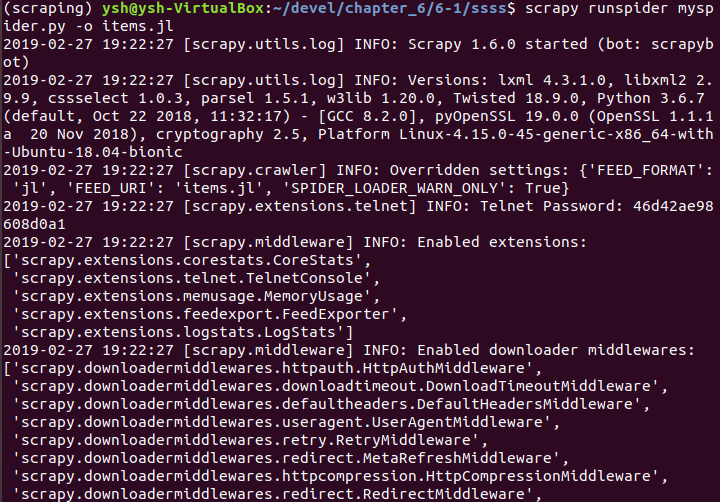
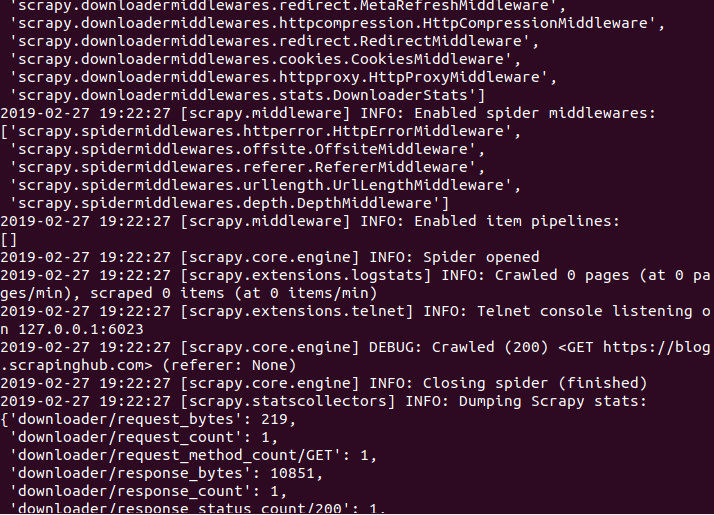
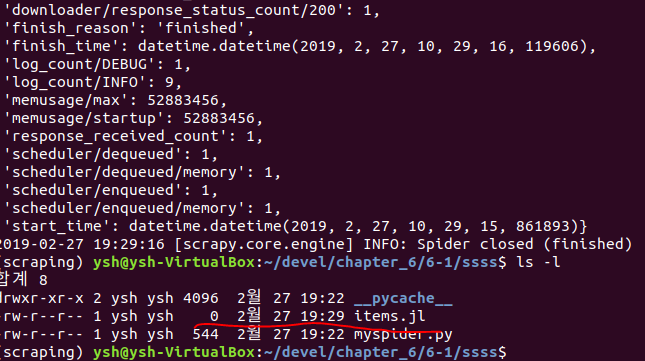

0
댓글
작성한 댓글 등록하기
안녕하세요.
크롤링하는 URL인 "https://blog.scrapinghub.com" 의 HTML이 예제코드와 다릅니다.
예제 코드가 작성되고 난 이후에 해당 사이트의 HTML이 수정된 것으로 추측되어 지네요.
아래와 같이 예제코드를 변경하고 scrapy를 실행하면 스크래핑이 되네요.
- import scrapy
- class BlogSpider(scrapy.Spider):
- # spider의 이름
- name = 'blogspider'
- # 크롤링을 시작할 URL 리스트
- start_urls = ['https://blog.scrapinghub.com']
- def parse(self, response):
- for url in response.css('ul li a::attr("href")').re('.*/tag/.*'):
- yield scrapy.Request(response.urljoin(url), self.parse_titles)
- def parse_titles(self, response):
- for post_title in response.css('div.post-header > h2 > a::text').extract():
- yield {'title': post_title}

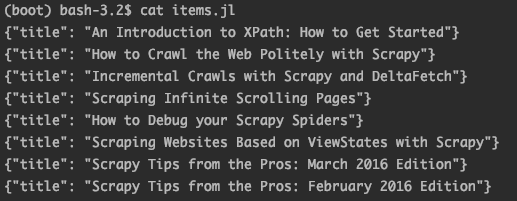
이 답변으로 문제를 해결하셨다면 채택 부탁드릴게요!
답변 작성
질문에 적합한 답변을 상세히 작성해 주시기 바랍니다.
답변이 찬성되면 태그평판 +2점이 적립, 반대되면 태그평판 -1점 차감됩니다.
답변이 채택되면 태그평판 +10점이 적립됩니다.
 python 게시판 정보
python 게시판 정보-
24질문수
-
29아카이브수
-
7채택수
-
2멤버수
python 질문 통계| 최근 30일 |
답변율
0%
|
채택율
0%
|
| 전체 |
답변율
16%
|
채택율
29%
|
최근에 등록된 질문
-
¢안전한놀이터 ¢텔레totobani ¢뉴토끼 ¢먹.튀검증totobani.com ¢슈어맨 ¢토.토벅스 ¢류현진제구경악
-
[★고용노동부 5년인증 우수훈련기관] 전액국비지원 IT 전문가 양성 모집
-
#의정부 #김포 #양주 #포천 #연천 #동두천 #허위비난 #3억달러 #우크라이나지원 #김학의 #직무유기 #북한 #경의선 #민주 #이화영 #술자리
-
주식레버리지임대 & 해외선물hts임대 텔레stock1981
-
카지노솔루션 | 토지노솔루션 | 홀덤솔루션 | 정품통합알 | 모아솔루션
-
안전카지노 - #해시게임sin-u33.com #언오버게임 #그래프게임 #안전코드5945 #섯다 #하이로우 #그래프게임hshsgame24.com #지뢰찾기 #소셜그래프게임
-
#하노이유흥달인 #하노이유흥문의 #베동떡지도.com #하노이밤문화정복 #미딩유흥거리 #카톡Ballcaphe #안전놀이터 #김하성3점홈런
-
fun88com.xyz ทางเข้าตรง: คาสิโนสดและการแทงบอลที่รวดเร็วและมั่นใจได้ในทุกวัน
-
fun88com.xyz ทางเข้าตรง คาสิโนสดและการแทงบอลที่รวดเร็วและปลอดภัยสำหรับทุกวัน
-
fun88com.xyz ทางเข้าตรง: คาสิโนสดและการแทงบอลที่รวดเร็วและปลอดภัยทุกวัน
-
[무료 세미나] "차세대 지능형 인프라 구축을 위한 온디바이스 AI" 세미나 개최 (4.29, 코엑스)
-
[무료교육] TensorFlow와 전이학습을 이용한 실전 데이터 분석 교육안내(04.22~04.24)
-
고벳솔루션 | 토지노솔루션 | 홀덤솔루션 | 정품통합알 | gobet솔루션 | 카지노솔루션
-
카지노솔루션 | 토지노솔루션 | 홀덤솔루션 | 정품통합알 | 모아솔루션
-
SBA 서울경제진흥원_마포5기 피그마로 완성하는 UXUI 실무 프로젝트 (~05/07)