스크래피 스파이더가 빈파일을 출력하는 이유를 모르겠어요!
- 1
-
0
책('파이썬을 이용한 웹크롤링과 스크레이핑' )에 첨부된 ch6-1의 myspider.py 입니다.
- import scrapy class BlogSpider(scrapy.Spider): # spider의 이름 name = 'blogspider' # 크롤링을 시작할 URL 리스트 start_urls = ['https://blog.scrapinghub.com'] def parse(self, response): for url in response.css('ul li a::attr("href")').re('.*/category/.*'): yield scrapy.Request(response.urljoin(url), self.parse_titles) def parse_titles(self, response): for post_title in response.css('div.entries > ul > li a::text').extract(): yield {'title': post_title}
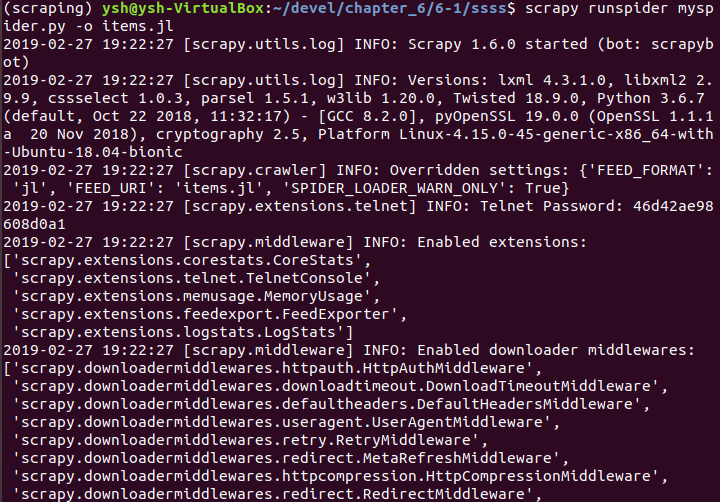
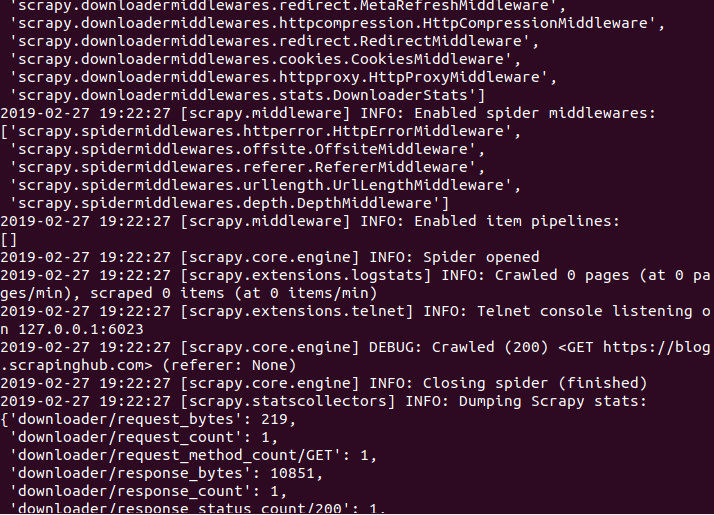
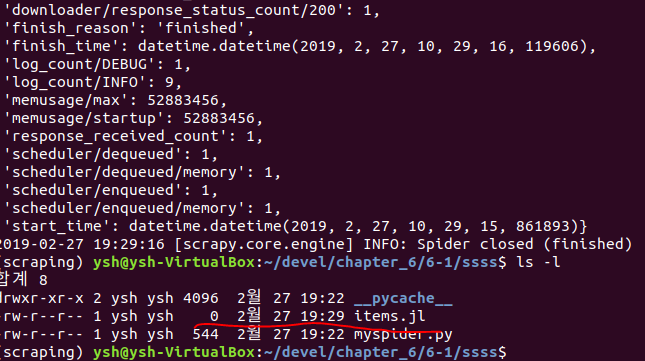

0
댓글
작성한 댓글 등록하기
안녕하세요.
크롤링하는 URL인 "https://blog.scrapinghub.com" 의 HTML이 예제코드와 다릅니다.
예제 코드가 작성되고 난 이후에 해당 사이트의 HTML이 수정된 것으로 추측되어 지네요.
아래와 같이 예제코드를 변경하고 scrapy를 실행하면 스크래핑이 되네요.
- import scrapy
- class BlogSpider(scrapy.Spider):
- # spider의 이름
- name = 'blogspider'
- # 크롤링을 시작할 URL 리스트
- start_urls = ['https://blog.scrapinghub.com']
- def parse(self, response):
- for url in response.css('ul li a::attr("href")').re('.*/tag/.*'):
- yield scrapy.Request(response.urljoin(url), self.parse_titles)
- def parse_titles(self, response):
- for post_title in response.css('div.post-header > h2 > a::text').extract():
- yield {'title': post_title}

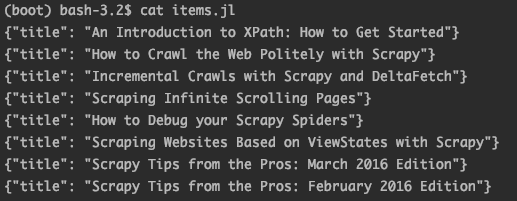
이 답변으로 문제를 해결하셨다면 채택 부탁드릴게요!
답변 작성
질문에 적합한 답변을 상세히 작성해 주시기 바랍니다.
답변이 찬성되면 태그평판 +2점이 적립, 반대되면 태그평판 -1점 차감됩니다.
답변이 채택되면 태그평판 +10점이 적립됩니다.
 python 게시판 정보
python 게시판 정보-
24질문수
-
29아카이브수
-
7채택수
-
2멤버수
python 질문 통계| 최근 30일 |
답변율
0%
|
채택율
0%
|
| 전체 |
답변율
16%
|
채택율
29%
|
최근에 등록된 질문
-
안전카지노 - #해시게임 #소셜그래프게임hshsgame24.com #지뢰찾기 #조작없는 #고추에이전시bet-tv22.com #추천5945 #부스타빗 #해시값 #구글검색
-
#하노이밤문화 #카톡junko7000 #하노이유흥추천 #베동떡지도.com #베트남유흥달인 #구글검색베동떡지도.com #안전놀이터 #김민재뜨거운결심
-
온라인카지노- ✨해시게임그래프hshsgame24.com✨해쉬게임 ✨지뢰찾기✨친구에이전시sin-s77.com✨추천79✨천원부터배팅✨돌아온부스타빗✨먹튀안전✨김민재뜨거운결심
-
∝바니툰 ∝먹.튀검증소 ∝티비다시보자 ∝늑대닷컴 ∝바니토.토totobani.com ∝텔레totobani ∝유아인프로포폴처방의사
-
[아이티윌부산]100%국비지원 비전공자/초보자도 가능한 IT 전문가 양성 훈련생 모집
-
[★고용노동부 5년인증 우수훈련기관] 전액국비지원 기업형 실무 인재 양성 자바웹개발자 과정!
-
토지노 솔루션 분양 임대 개발
-
[취업과정8기] 5월 국비 웹 개발자 양성 무료교육 과정
-
카지노솔루션 | 토지노솔루션 | 홀덤솔루션 | 정품통합알 | 모아솔루션
-
주식 레버리지 프로그램/해외선물 프로그램 분양 임대
-
⭐️⭐️ 토지노 솔루션 업계 1위 ⭐️⭐️ 퍼펙트솔루션
-
온라인카지노- ●해시게임●친구에이전시sin-s77.com ●하이로우 ●바이너리 ●해쉬값 ●먹튀없는 ●코드79 ●안전놀이터hshsgame24.com ●먹튀안전 ●온라인슬롯 ●취소된
-
에이콘아카데미 강남, 자바(JAVA)중심 풀스택 캠프
-
더조은아카데미 종로, 빅데이터분석(with 파이썬)과 엘라스틱서치를 활용한 자바(Java)웹개발자양성
-
카지노솔루션 | 토지노솔루션 | 홀덤솔루션 | 정품통합알 | 모아솔루션